Giới Thiệu Chung
Trong kỷ nguyên bùng nổ của trí tuệ nhân tạo (AI), các mô hình ngôn ngữ lớn (Large Language Models – LLMs) như GPT, LLaMA, Claude hay Gemini đang ngày càng được ứng dụng rộng rãi. Tuy nhiên, hiệu năng GPU khi chạy các mô hình này không hề tuyến tính theo kích thước mô hình – ngược lại, sự khác biệt có thể rất lớn, đặc biệt khi triển khai trên các hệ thống máy chủ hoặc workstation chuyên dụng.
Vậy kích thước mô hình LLM ảnh hưởng ra sao tới hiệu suất GPU? Tại sao một GPU có thể hoạt động “nhàn rỗi” với mô hình nhỏ, nhưng lại bị nghẽn tài nguyên với mô hình lớn? Hãy cùng PC79.VN đi sâu vào từng lớp để khám phá sự khác biệt hiệu năng GPU theo kích thước mô hình LLM.
Phân Loại Kích Thước Mô Hình LLM
Trước hết, cần hiểu rõ kích thước mô hình LLM thường được đo theo số lượng tham số (parameters), đơn vị tính là tỷ tham số (B = Billion). Các mô hình phổ biến có thể được chia thành:
Mô hình nhẹ (<7B): Ví dụ: LLaMA 2 7B, Mistral 7B
Mô hình trung bình (7B – 30B): Ví dụ: LLaMA 2 13B, Mixtral 12.7B, GPT-J
Mô hình lớn (30B – 65B): Ví dụ: LLaMA 2 65B, Falcon 40B
Mô hình cực lớn (100B+): Ví dụ: GPT-3, Claude Opus, Gemini Ultra (chạy chủ yếu trên hạ tầng đám mây)
Kích thước mô hình càng lớn thì yêu cầu tài nguyên GPU (VRAM, băng thông bộ nhớ, tốc độ tensor) càng cao. Câu hỏi đặt ra là: GPU nào chạy mô hình nào hiệu quả nhất?
GPU Xử Lý LLM: Những Thành Phần Cốt Lõi Ảnh Hưởng Đến Hiệu Năng
Hiệu năng GPU trong xử lý LLM phụ thuộc vào 4 yếu tố chính:
1. Bộ nhớ VRAM
Các mô hình LLM lớn yêu cầu tải toàn bộ mô hình vào VRAM.
Ví dụ:
LLaMA 7B (float16) cần ~13GB VRAM
LLaMA 13B cần ~24GB VRAM
LLaMA 65B cần ~65–130GB VRAM (tùy batch size)
Do đó, nếu GPU có VRAM <16GB (ví dụ: RTX 4060 Ti) sẽ không đủ để chạy inference mô hình 13B trở lên, trừ khi dùng kỹ thuật offloading.
2. Băng thông bộ nhớ (Memory Bandwidth)
Các mô hình lớn cần luân chuyển dữ liệu rất nhanh giữa các phần tử tính toán (Tensor Cores).
GPU dòng cao cấp như RTX 4090 (1,008 GB/s) hay A100 80GB HBM2e (2,039 GB/s) vượt trội hơn so với RTX 4070 (504 GB/s).
3. Hiệu năng tensor (Tensor TFLOPS)
LLM sử dụng rất nhiều phép toán tensor (matrix multiplication).
GPU có Tensor Core mạnh (ví dụ A100, H100, RTX 4090) sẽ cho hiệu suất gấp nhiều lần so với dòng gaming tầm trung như RTX 4060 hoặc RTX 3070.
4. Kiến trúc GPU và hỗ trợ phần mềm
Hỗ trợ phần mềm như Flash Attention, Quantization (4-bit, 8-bit), vLLM, ExLlama cũng ảnh hưởng đến tốc độ inference hoặc fine-tune mô hình.
GPU kiến trúc mới như Ada Lovelace (RTX 40 Series) hoặc Hopper (H100) có khả năng tận dụng các tối ưu mới tốt hơn.
LLM nhỏ vs. LLM lớn – benchmark cái nào?
Trong các bài đánh giá hiệu năng GPU gần đây tại Puget Systems, chúng tôi thường sử dụng mô hình Phi-3-Mini-4K-Instruct (3.8 tỷ tham số) vì:
- Nhanh: Benchmark hoàn tất trong thời gian ngắn.
- Gọn nhẹ: Dễ chạy trên hầu hết GPU, kể cả dòng 4GB VRAM.
- Phù hợp: So sánh được nhiều GPU trong cùng điều kiện.
So sánh đơn giản: Mô hình LLM như bộ lọc nước nhiều lớp. Càng nhiều lớp (tham số), kết quả càng “sạch” nhưng tốn thời gian xử lý.
Dù vậy, có nhiều người dùng thắc mắc: “Kết quả benchmark từ mô hình nhỏ có thật sự chính xác khi tôi muốn dùng mô hình lớn?”
Để trả lời câu hỏi đó, chúng tôi tiến hành bài test hiệu năng giữa Phi-3 Mini (3.8B) và Phi-3 Medium (14B) trên nhiều GPU khác nhau.
Cấu hình thử nghiệm benchmark LLM
Thông số phần cứng
- CPU: AMD Ryzen Threadripper PRO 7975WX (32 nhân)
- Bo mạch chủ: ASUS Pro WS WRX90E-SAGE SE
- RAM: 128GB DDR5 ECC (8x16GB @5600MHz)
- Tản nhiệt: Asetek 360mm
- Ổ cứng: Samsung 980 Pro 2TB
- Nguồn: Super Flower 1600W Platinum
- Hệ điều hành: Windows 11 Pro 23H2
GPU được thử nghiệm
| GPU | VRAM |
| NVIDIA RTX 4090 | 24GB |
| NVIDIA RTX 4080 SUPER | 16GB |
| NVIDIA RTX 4080 | 16GB |
| NVIDIA RTX 3090 | 24GB |
- Driver NVIDIA: 560.70
- Llama.cpp build: 3140 (CUDA 12.2.0)
- Mô hình sử dụng:
- Phi-3-Mini-4K-Instruct (3.8B tham số)
- Phi-3-Medium-4K-Instruct (14B tham số)
- Định dạng: Q8_0 GGUF (8-bit)
Cài đặt benchmark
- Xử lý Prompt: 512 tokens
- Sinh Token: 128 tokens
- Số vòng lặp: 25 lần/test – lấy trung bình
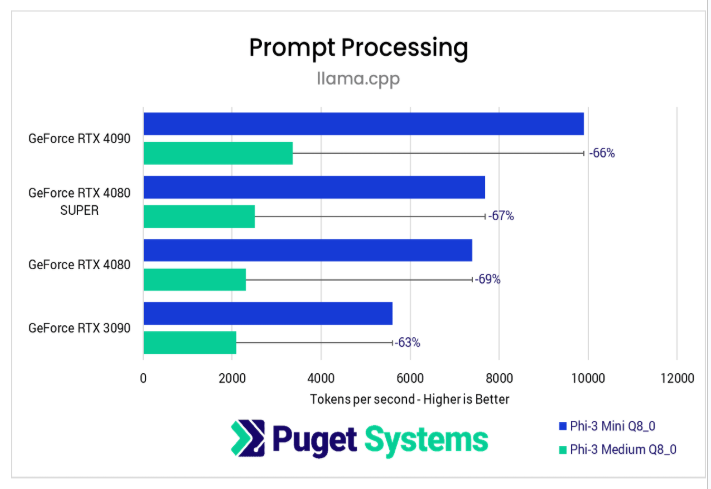
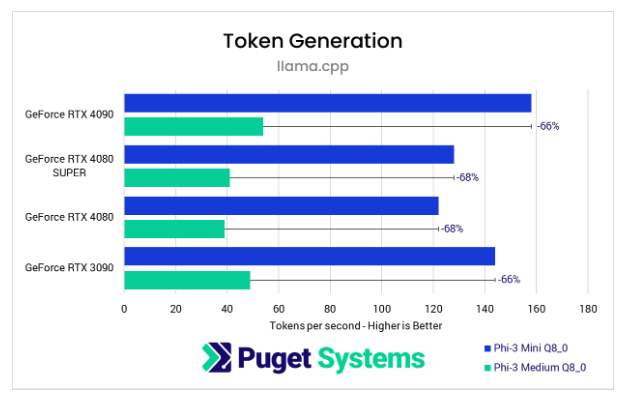
Hiệu năng GPU: Có thay đổi khi mô hình lớn hơn?
Giai đoạn 1: Xử lý Prompt
- Chênh lệch hiệu năng giữa các GPU chỉ dưới 5%, cao nhất là ~6%.
- Điều này cho thấy dù đổi kích thước mô hình, tương quan hiệu năng giữa GPU vẫn giữ nguyên.
- Phi-3 Mini đủ chính xác để đánh giá hiệu năng trong cùng một phân khúc GPU.
Kết luận nhanh: Dùng LLM nhỏ để benchmark hiệu năng tương đối là hoàn toàn hợp lý!
Giai đoạn 2: Sinh Token
- Hiệu năng giảm 66–68% khi chuyển từ Phi-3 Mini (3.8B) sang Phi-3 Medium (14B).
- Sự sụt giảm này đều nhau trên tất cả GPU, không làm thay đổi thứ hạng GPU.
- Tức là, nếu GPU A nhanh hơn GPU B với mô hình nhỏ → thì với mô hình lớn, A vẫn nhanh hơn B tương tự.
Kết luận: Có thể benchmark bằng LLM nhỏ hay không?
Có – và rất hiệu quả!
- Benchmark bằng LLM nhỏ như Phi-3 Mini giúp tiết kiệm thời gian, công sức, và vẫn đưa ra được so sánh hiệu năng chính xác giữa các GPU.
- Dù mô hình lớn có thể cho ra số liệu sát thực tế hơn, nhưng thời gian test dài và yêu cầu VRAM cao khiến việc so sánh hàng loạt GPU trở nên bất khả thi.
- Với độ lệch hiệu năng đồng đều khi mở rộng mô hình, bạn hoàn toàn có thể ngoại suy kết quả từ mô hình nhỏ sang mô hình lớn hơn.
Bạn nên chọn gì?
| Nếu bạn… | Lời khuyên |
| Làm inference LLM quy mô nhỏ đến trung bình | Dùng benchmark với mô hình nhỏ là đủ |
| Làm việc với LLM cực lớn (30B–70B tham số) | Nên test thêm trên mô hình lớn nếu có thể |
| So sánh GPU để chọn mua phù hợp ngân sách | Hoàn toàn nên dùng benchmark Phi-3 Mini |